






随着大数据时代的到来,实时数据处理成为了企业不可或缺的一环,作为开源流处理平台中的佼佼者,Kafka在实时数据处理领域扮演着举足轻重的角色,十二月,让我们深入探讨Kafka实时处理的三大要点,助你轻松驾驭大数据流。
随着数据量的不断增长,企业需要快速、准确地处理和分析这些数据以获取有价值的信息,Kafka以其高吞吐量、可扩展性和容错性等特点,成为大数据领域炙手可热的实时处理工具,本文将重点讨论Kafka在实时处理方面的三大要点,帮助读者更好地理解和应用这一技术。
要点一:Kafka基本概念与架构
1、Kafka概述
Kafka是一个分布式流处理平台,主要用于构建实时数据流管道和流应用,它允许发布和订阅记录流,同时提供容错和可扩展性。
2、Kafka架构
Kafka架构主要由三大组件构成:Producer(生产者)、Broker(代理)和Consumer(消费者),生产者负责发布数据到Kafka集群,代理负责存储和管理数据,消费者负责从Kafka集群订阅并消费数据。
要点二:Kafka在实时处理中的应用优势
1、高吞吐量
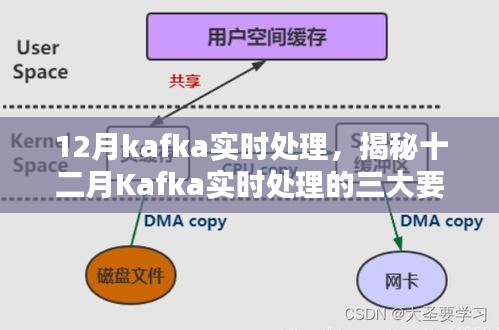
Kafka具有极高的吞吐量,能够处理大规模的数据流,其采用发布-订阅模式,支持并发处理,使得数据吞吐能力得到大幅提升。
2、延迟低
Kafka支持实时数据处理,具有低延迟的特点,数据在Kafka中存储时,消费者可以实时订阅并消费,从而实现低延迟的实时处理。
3、容错性与可扩展性
Kafka具有良好的容错性和可扩展性,数据在Kafka集群中复制并持久化存储,即使部分节点失效,数据也不会丢失,Kafka集群支持动态扩展,可根据需求增加或减少节点。
四、要点三:十二月Kafka实时处理的最佳实践
1、合理规划主题与分区数
在Kafka中,主题和分区数的规划对实时处理的性能具有重要影响,应根据数据量、消费者并发需求等因素合理规划主题与分区数,以提高实时处理的效率。
2、优化消费者消费策略
消费者消费策略是影响Kafka实时处理效果的关键因素之一,应根据实际需求选择合适的消费策略,如负载均衡、消息确认机制等,以确保数据的实时性和准确性。
3、利用Kafka Streams进行流式处理
Kafka Streams是Kafka的一个强大功能,允许用户在Kafka平台上进行流式处理,通过Kafka Streams,可以实时地对数据流进行转换、聚合和分析,从而满足各种实时业务需求。
十二月,让我们深入探索Kafka实时处理的三大要点,通过了解Kafka的基本概念与架构、应用优势以及最佳实践,我们可以更好地应用Kafka进行实时数据处理,在未来的大数据时代,掌握Kafka实时处理技术将为企业带来更大的价值,希望本文能助你在Kafka的实时处理领域轻松前行,驾驭大数据流。
转载请注明来自河南双峰网袋厂,本文标题:《揭秘十二月Kafka实时处理的三大要点与策略》





 豫ICP备19030322号-1
豫ICP备19030322号-1
还没有评论,来说两句吧...